Accelerating Yade’s FlowEngine with GPU¶
(Note: we thank Robert Caulk for preparing and sharing this guide)
Summary¶
This document contains instructions for adding Suite Sparse’s GPU acceleration to Yade’s Pore Finite Volume (PFV) scheme as demonstrated in [Caulk2019]. The guide is intended for intermediate to advanced Yade users. As such, the guide assumes the reader knows how to modify and compile Yade’s source files. Readers will find that this guide introduces system requirements, installation of necessary prerequisites, and installation of the modified Yade. Lastly, the document shows the performance enhancement expected by acceleration of the factorization of various model sizes.
Hardware, Software, and Model Requirements¶
- Hardware:
CUDA-capable GPU with >3 GB memory recommended (64 mb required)
- Software:
NVIDIA CUDA Toolkit
SuiteSparse (CHOLMOD v2.0.0+)
Metis (comes with SuiteSparse)
CuBlas
OpenBlas
Lapack
- Model:
Fluid coupling (Pore Finite Volume aka Yade’s “FlowEngine”)
>10k particles, but likely >30k to see significant speedups
Frequent remeshing requirements
Install CUDA¶
The following instructions to install CUDA are a boiled down version of these instructions.
lspci | grep -i nvidia #Check your graphics card
# Install kernel headers and development packages
sudo apt-get install linux-headers-$(uname -r)
#Install repository meta-data (see **Note below):
sudo dpkg -i cuda-repo-<distro>_<version>_<architecture>.deb
sudo apt-get update #update the Apt repository cache
sudo apt-get install cuda #install CUDA
# Add the CUDA library to your path
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Note: use this tool to determine your <distro>_<version>_<architecture> values.
Restart your computer.
Verify your CUDA installation by navigating to /usr/local/cuda/samples and executing the make command. Now you can navigate to /usr/local/cuda/samples/1_Utilities/deviceQuery/ and execute ./deviceQuery . Verify the Result = PASS.
Install OpenBlas, and Lapack¶
Execute the following command:
sudo apt-get install libopenblas-dev liblapack-dev
Install SuiteSparse¶
Download the SuiteSparse package and extract the files to /usr/local/. Run make config and verify CUDART_LIB and CUBLAS_LIB point to your cuda installed libraries. The typical paths will follow CUDART_LIB=/usr/local/cuda-x.y/lib64 and CUBLAS_LIB=/usr/local/cuda-x.y/lib64. If the paths are blank, you may need to navigate to to CUDA_PATH in /usr/local/SuiteSparse/SuiteSparse_config/SuiteSparse_config.mk and modify it manually to point to your cuda installation. Navigate back to the main SuiteSparse folder and execute make. SuiteSparse is now compiled and installed on your machine.
Test CHOLMOD’s GPU functionality by navigating to SuiteSparse/CHOLMOD/Demo and executing sh gpu.sh. Note: you will need to download the nd6k.mtx from here and put it in your home directory.
Compile Yade¶
Following the instructions outlined here, run cmake with -DCHOLMOD_GPU=ON and -DSUITESPARSEPATH=/usr/local/SuiteSparse (or your other custom path). Check the output to verify the paths to CHOLMOD (and dependencies such as AMD), SuiteSparse, CuBlas, and Metis are all identified as the paths we created when we installed these packages. Here is an example of the output you need to inspect:
-- Found Cholmod in /usr/local/SuiteSparse/lib/libcholmod.so
-- Found OpenBlas in /usr/lib/libopenblas.so
-- Found Metis in /usr/local/SuiteSparse/lib/libmetis.so
-- Found CuBlas in /usr/local/cuda-x.y/libcublas.so
-- Found Lapack in /usr/lib/liblapack.so
If you have multiple versions of any of these packages, it is possible the system finds the wrong one. In this case, you will need to either uninstall the old libraries (e.g. sudo apt-get remove libcholmod if the other library was installed with apt-get) or edit the paths within cMake/Find_____.cmake. If you installed a version of Cuda in a different location than /usr/local, you will need to edit cMake/FindCublas.cmake to reflect these changes before compilation.
Metis is compiled with SuiteSparse, so the Metis library and Metis include should link to files within usr/local/SuiteSparse/. When ready, complete installation with make -jX install. Keep in mind that adding CHOLMOD_GPU alters useSolver=4 so to work with the GPU and not the CPU. If you wish to useSolver=4 with the CPU without unintended side effects (possible memory leaks), it is recommended to recompile with CHOLMOD_GPU=OFF. Of course, useSolver=3 should always work on the CPU.
Controlling the GPU¶
The GPU accelerated solver can be activated within Yade by setting flow.useSolver=4`. There are several environment variables that control the allowable memory, allowable GPU matrix size, etc. These are highlighted within the CHOLMOD User Guide, which can be found in SuiteSparse/CHOLMOD/Doc. At the minimum, the user needs to set the environment variable by executing export CHOLMOD_USE_GPU=1. It is also recommended that you designate half of your available GPU memory with export CHOLMOD_GPU_MEM_BYTES=3000000000 (for a 6GB graphics card), if you wish to use the multithread=True functionality. If you have a multi-gpu setup, you can tell Yade to use one (or both GPUs with SuiteSparse-4.6.0-beta) by executing export CUDA_VISIBLE_DEVICES=1, where 1 is the GPU you wish to use.
Performance increase¶
[Catalano2012] demonstrated the performance of DEM+PFV coupling and highlighted its strengths and weaknesses. A significant strength of the DEM+PFV coupling is the asymptotic nature of triangulation costs, volume calculation costs, and force calculation costs ( [Catalano2012], Figure 5.4). In other words, increasing the number of particles beyond ~200k results in negligible additional computational costs. The main weakness of the DEM+PFV coupling is the exponential increase of computational cost of factoring and solving increasingly larger systems of linear equations ( [Catalano2012], Figure 5.7). As shown in Fig. fig-cpuvsgpu, the employment of Tesla K20 GPU decreases the time cost of factorization by up to 75% for 2.1 million DOFs and 356k particles.
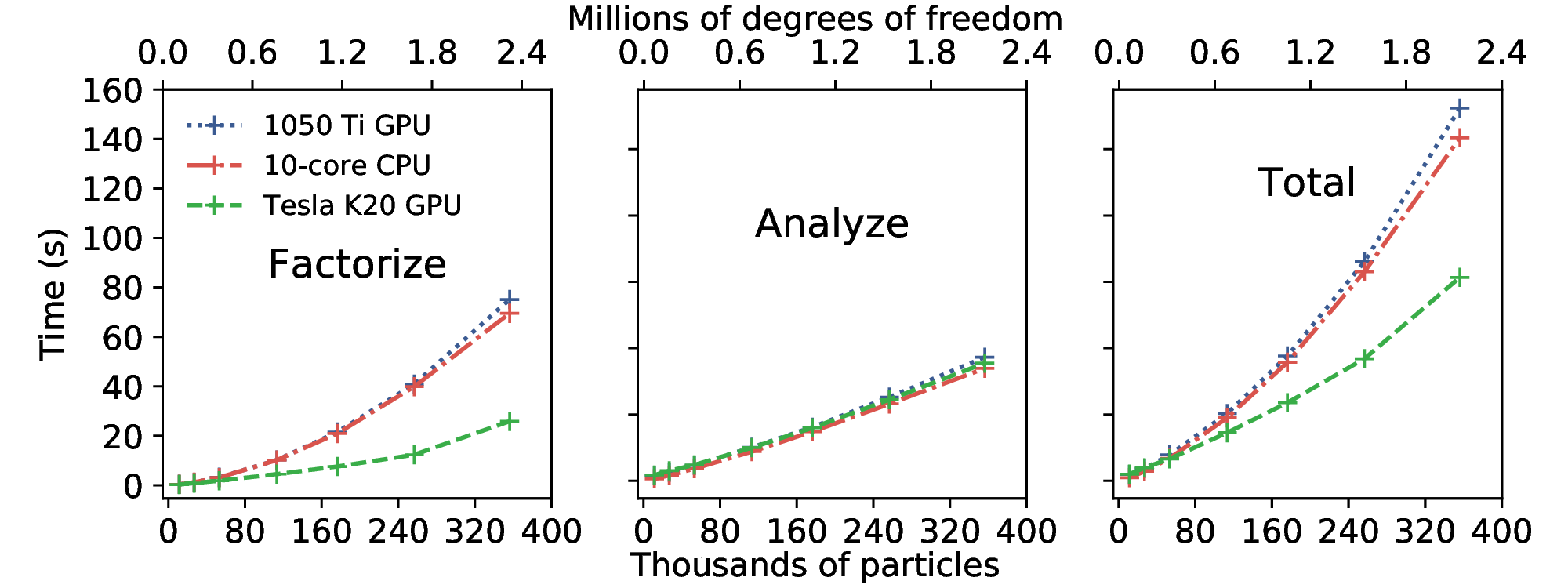
Time required to factorize and analyze various sized matrices for 10-core CPU, 1050Ti GPU, and Tesla K20 GPU [Caulk2019].¶
Note: Tesla K20 5GB CPU + 10-core Xeon E5 2.8 GHz CPU